
Growing from hundreds or thousands of distributors to 100,000+ is a milestone many network-based businesses (MLM, direct selling, network marketing, affiliate networks) aspire to. But scaling brings not just opportunities — it brings new, complex failure modes.  Many organizations that soared early on falter under the weight of volume: data bottlenecks, commission miscalculations, system slowdowns, trust issues, fraud, customer support overload, compliance risks, and so on. In this article, we’ll dive deep into what breaks, why it breaks, and — more importantly — how best practices and modern architectures help you survive and thrive at scale.
Many organizations that soared early on falter under the weight of volume: data bottlenecks, commission miscalculations, system slowdowns, trust issues, fraud, customer support overload, compliance risks, and so on. In this article, we’ll dive deep into what breaks, why it breaks, and — more importantly — how best practices and modern architectures help you survive and thrive at scale.
The global MLM software market, valued at roughly USD 600 million in 2024, is projected to more than double by 2031 (CAGR ~9.97 %) Verified Market Research.
In fact other forecasts peg the broader direct-selling / network software space at CAGR ~10–11 % over the next 5–7 years htfmarketinsights.com.
That means more competitors, more customers, and more demands on infrastructure. If your back-end can’t keep up, your front-end (distributors) will revolt.
As you cross thresholds like 10K → 50K → 100K distributors, you can expect nonlinear growth in load — doubling users doesn’t double load, it often quadruples it, because interactions among users multiply (downline, reporting, commissions, cross-team links).
Below are the major failure points that many scaling networks experience — and in many cases, already live ones have been hit by these.
| Challenge | What Fails / Symptoms | Why It Happens |
|---|---|---|
| Database bottleneck & consistency issues | Slow queries on downline trees, incorrect commission updates, DB deadlocks, replication lag | Graph and hierarchical queries (e.g. “who is my 5th generation downline”) blow up relational DB indexes; concurrent writes create race conditions |
| Commission engine overload | Payouts delayed by hours or days, negative balances, mismatches | Complex compensation plans (multi-leg, bonus, performance splits) lead to combinatorial explosion of calculations at scale |
| APIs & microservice latency | Mobile apps time out, dashboards lag, distributor churn | As services are split, network hops and inter-service delays accumulate; synchronous APIs cause blocking |
| Caching, cache invalidation, and freshness | Discrepancies between displayed commission vs actual, stale dashboards | Cache invalidation in a heavy write environment is notoriously hard — stale reads vs correctness tradeoffs |
| Concurrency, locking, and race conditions | Two distributors see conflicting states, duplicate commissions, data corruption | High concurrency — many simultaneous operations on shared data — exacerbates locking design mistakes |
| Infrastructure (compute, network, storage) limits | Throttling, crashes, overload | Under-provisioned architecture, monolithic designs, vertical scaling ceilings |
| Security, fraud, and compliance | Vulnerability exploits, fake accounts, account takeovers, regulatory exposure | At scale, fraudsters focus on edge cases, attacks, and automated scripting; compliance across geographies becomes harder |
| Support, training, operations overhead | Customer support queues, escalations, manual fixes, SLA failures | As volume increases, human processes that once sufficed will break down |
Let’s look at some concrete demonstrations:
Suppose each distributor maintains references to all ancestors up to 10 levels and each node triggers commission updates to upstream nodes dynamically. A single purchase can then spawn tens or hundreds of DB writes. At 100K distributors, that becomes millions of writes per hour.
Many systems that push naive relational joins or unindexed hierarchical queries degrade from sub-100ms responses to seconds or timeouts. This is why modern networks use graph databases (Neo4j, Amazon Neptune) or specialized tree / closure tables to maintain efficient ancestry queries.
Some scalable MLM platforms today claim to handle 1 million users using microservices, distributed databases, auto-scaling, and optimized caching.
However, a key test is how fast the engine can compute payouts when 100,000 distributors are active in a promotion. A well-architected commission engine should complete complex multi-tier payout calculations in under 10 seconds — anything beyond invites cascading bottlenecks.
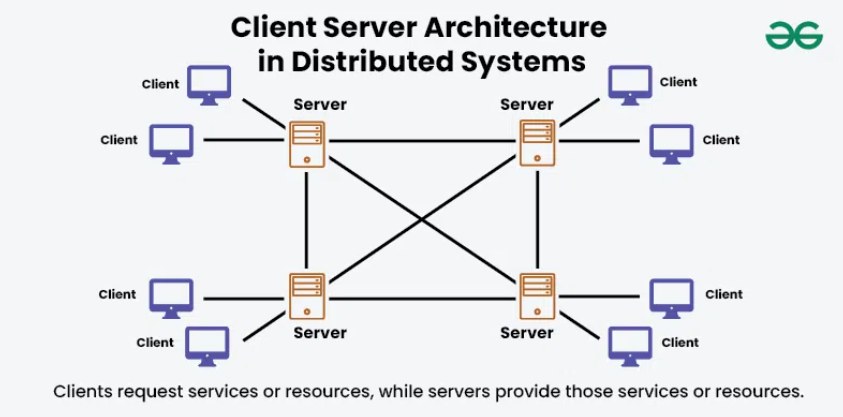
To scale past 100K distributors, organizations need to shift from monoliths to scalable, modular architecture. Here are critical practices and patterns:
Split your system into domains: user management, commission engine, payouts, reporting, notifications, etc. Each runs independently. This lets each domain scale differently. But note: inter-service calls impose network latency, so design for idempotent, asynchronous interactions. en.wikipedia.org
Use message brokers (Kafka, RabbitMQ) to decouple synchronous load. For instance, a purchase event triggers a chain of asynchronous workflows (update tree, compute commissions, notify). This smooths spikes.
For hierarchical network queries, graph databases are ideal; for high write volume, NoSQL (Cassandra, DynamoDB) or sharded relational DBs help. Use horizontal scaling rather than vertical upgrades. wrike.com
Layer caching (Redis, Memcached) for read-heavy endpoints (dashboard, genealogy). For writes, use write-through or read-after-write consistency patterns — but design your invalidation carefully to avoid stale or inconsistent reads.
Set up your compute / container clusters (e.g. Kubernetes, serverless) with auto-scaling. Provision infrastructure by code (Terraform, CloudFormation) to reduce manual drift.
Under load, degrade noncritical endpoints gracefully. Use circuit breakers to protect core services (commission engine) from overload.
Use APM tools (New Relic, Datadog), logs, distributed tracing (OpenTelemetry) to detect latencies, errors, and hotspots. Run chaos experiments to see how your system behaves under node failure or high traffic surges.
As you scale, you need real-time anomaly detection (e.g. AI/ML models to detect duplicate accounts, fake purchases, unusual commission claims). Logging, audit trails, role-based permissions, IP throttling become non-negotiable.
If your distributors span multiple countries, you may need data residency, local tax rules, and local compliance branching — implement geo-sharded infrastructure and compliance layers.
As of 2025, several trends are reshaping how high-scale networks handle the above:
Some next-gen platforms use predictive analytics to forecast downline growth, identify top performers, and automate training nudges.
Using blockchain or internal tokens to manage micropayments, commissions, or rewards in a scalable, transparent way.
Tools that allow distributors or back-office staff to configure compensation rules, promotions, and workflows without heavy dev cycles.
Using FaaS (Lambda, Azure Functions) to absorb bursts (e.g. midnight batch jobs, monthly closing) without overprovisioning.
To reduce latency for distributors across the globe, many networks deploy in multiple cloud regions or across cloud providers.
Systems now embed tracing, metrics, and logs by default, not as an afterthought — ensuring scaling issues surface early.
Prebuilt modules for KYC/AML, GDPR, tax deduction, local regulatory rules that plug into your network engine.
Here’s a simplified flow of how a modern commissioning system handles a sale at large scale:
Because each step is decoupled, you can add more instances of commission engine or payout services as needed. If one fails, circuit breakers prevent cascading outages.
If built naively (all in one process), a single high-volume sale burst might block all other requests.
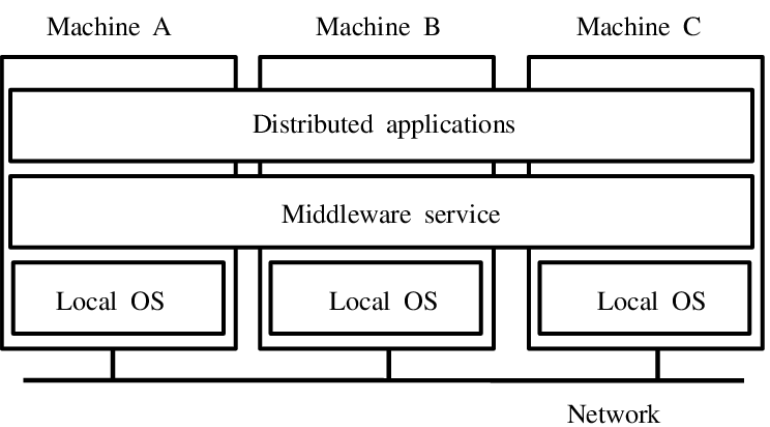
Some MLM software vendors explicitly market that they can support 1 million users via microservices, distributed DB, and optimized caching layers.
However, many legacy networks collapse when user base crosses 30,000–50,000 because they underestimated the cascading effect of depth (transactions times levels) and concurrency.
In non-MLM but analogous systems (e.g. large affiliate networks, relational SaaS), it’s common to see 3×–5× increase in API timeout errors or 500 errors when scaling beyond a certain threshold — unless architecture is improved proactively.
When scaling, monitor these KPIs and thresholds:
Reaching 100,000+ distributors is a tremendous milestone — but survival requires more than ambition. It demands a carefully engineered architecture, robust concurrency handling, modular services, distributed data stores, real-time observability, and a culture of scale thinking.
When leaders treat scaling not as a future problem but as a present design constraint, the transition to 100K becomes less of a leap and more of a managed evolution.
If you’d like me to walk you through a scalable blueprint or audit your current design, I’d be happy to help.
1. What does scalability mean in MLM networks?
Scalability refers to the ability of your MLM system to handle exponential growth — more distributors, transactions, and commissions — without performance degradation.
2. Why do scalability issues occur after 100,000 distributors?
Most MLM platforms use legacy databases or monolithic structures that cannot efficiently process large hierarchical relationships or commission calculations at high volume.
3. What are common symptoms of poor scalability?
Slow dashboards, delayed commissions, data mismatches, timeout errors, and frequent system crashes are the first red flags of scalability breakdown.
4. How can businesses test MLM scalability before issues arise?
Load testing tools and simulated network transactions can help predict how your infrastructure performs under increased user load before real failures happen.
5. What technologies support scalable MLM systems?
Microservices architecture, distributed databases (like MongoDB, Cassandra), caching layers (Redis), and event-driven systems are key for scaling.
6. Can traditional relational databases handle MLM growth?
Not efficiently beyond 10K–50K distributors — hierarchical queries become too complex. Graph databases or hybrid data models are more scalable options.
7. How do commission engines handle 100K+ users?
Modern systems use asynchronous event-driven commission engines that compute payouts in parallel, dramatically reducing processing time.
8. What are the top trends in MLM scalability for 2025?
AI-driven fraud detection, blockchain-based transparency, serverless architectures, and predictive scaling analytics are major trends in 2025.
9. How does scaling affect security and compliance?
Larger networks increase fraud risk and compliance obligations. Scalable systems include KYC, anti-fraud monitoring, and global tax compliance modules.
10. What’s the ROI of investing in scalable MLM architecture?
Businesses with scalable systems reduce downtime, support costs, and churn — improving ROI by up to 40% due to smoother distributor experiences.
👉 Try the official MLM Software Demo for Your MLM Business
and experience what MLM Software looks like when it’s powered by the best.
💌 Or, check out our blog
to compare top direct-selling companies, get insider reviews, and learn how to grow your income ethically in the wellness niche.